文章內容
遺傳密碼

請自行調高解析度
❒ 蛋白質的合成
➤轉錄(Transcription):發生在細胞核內
生物體利用中心教條合成蛋白質的流程如<圖一(a)>所示,假設某一段DNA密碼股的序列為ATG-GAG-GTG…,則DNA模版股的序列為TAC-CTC-CAC...,要注意密碼股與模版股是由於氫鍵吸引在一起的,所以彼此互相配對。由DNA模版股產生mRNA的序列為AUG-GAG-GUG...,這個過程稱為「轉譯(Translation)」。有沒有發現mRNA的序列與DNA密碼股其實是一樣的呢?只不過是將DNA密碼股的T改成mRNA的U而已,因為T只會出現在DNA裡,U只會出現在RNA裡,這也就是為什麼DNA密碼股要叫做「密碼股」了,因為密碼股的序列就是mRNA的序列,也才是用來合成蛋白質的序列。
➤轉譯(Translation):發生在核糖體上
接下來mRNA移動到核糖體上,經由tRNA與rRNA的協助,產生蛋白質,依序為AUG產生「Met(甲硫氨酸)」、GAG產生「Glu(麩氨酸)」、GUG產生「Val(纈氨酸)」…,如<圖一(b)>所示。
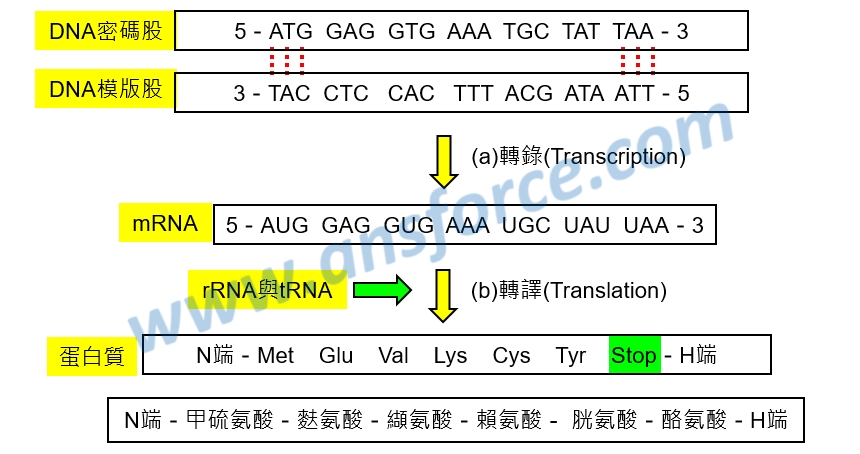
圖一 中心教條的轉錄與轉譯。
❒ 標準遺傳密碼
經由前面的介紹,大家有沒有覺得,這實在太神奇了!原來人體裡有這樣的規則,mRNA每三個核苷酸序列轉譯成一個胺基酸,而mRNA的核苷酸序列又是由DNA轉錄而來,換句話說,DNA其實是紀錄了「要使用那種胺基酸序列來合成蛋白質」。前面曾經問過這樣的問題:不同的胺基酸排列順序,決定了氫鍵的位置;氫鍵的位置決定了蛋白質的三級結構;蛋白質的三級結構決定了活性中心的形狀;活性中心的形狀決定了這個蛋白質的功能。那麼是誰決定了胺基酸的排列順序呢?答案揭曉囉!原來是DNA,所以DNA的核苷酸序列決定了mRNA的核苷酸序列;mRNA的核苷酸序列決定了蛋白質的胺基酸序列;而蛋白質的胺基酸序列決定了生物體的一切,包括:是動物還是植物、是年輕還是老年、是聰明還是愚笨、長的帥不帥美不美,顯然生物體內DNA的核苷酸序列決定了生物的一切,所以我們稱DNA為「遺傳密碼」。
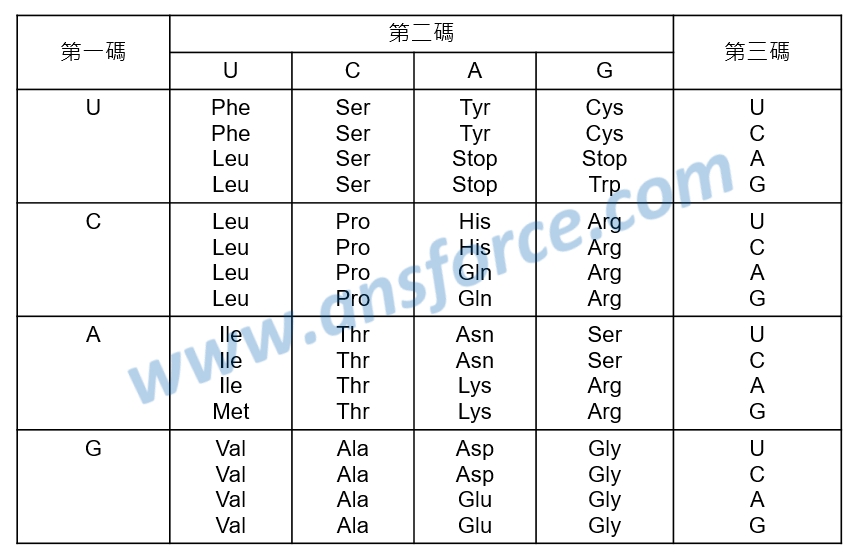
那麼,到底mRNA每三個核苷酸序列如何對應一個胺基酸呢?由於三個核苷酸序列可能有43=64種排列組合,科學家發現它們之間的對應關係如<表一>所示,我們稱為「標準遺傳密碼表」。值得注意的是,UAA、UAG、UGA對應到的是「Stop」,Stop並不是胺基酸,而是代表「停止」,意思是這個蛋白質「到此為止」,如<表一>所示。此外,大部分蛋白質的第一個胺基酸都是「Met(甲硫氨酸)」,換句話說,大部分mRNA的最前面三個核苷酸都是「AUG」,至於是什麼原因目前科學家還不是很確定。
表一 標準遺傳密碼表。
資料來源:李權益,分子生物學,合記圖書出版社。<我要買書>
【動動手】
利用前面的例子,假設mRNA的序列為AUG-GAG-GUG...,大家練習查查看標準遺傳密碼表吧!
➤第一碼為A、第二碼U、第三碼G:由<表一>中可以以查出對應的胺基酸為「Met(甲硫氨酸)」。
➤第一碼為G、第二碼A、第三碼G:由<表一>中可以查出對應的胺基酸為「Glu(麩氨酸)」。
➤第一碼為G、第二碼U、第三碼G:由<表一>中可以查出對應的胺基酸為「Val(纈氨酸)」。
【有此一說】
嚇到了吧!原來生物體有這樣的規則,所以才會有人覺得,「硬碟」是人類用來儲存二進位資料(0與1)的元件;而「人類」其實是外星人用來儲存四進位資料(A、T、G、C)的元件,呵呵~真是科幻電影看太多了。不過硬碟只能儲存二進位的資料(由0與1來排列組合),而人類可以儲存四進位的資料(由A、T、G、C來排列組合),顯然外星人的文明比人類還高一點:P。
❒ 標準遺傳密碼的特性
由<表一>可以看出,標準遺傳密碼具有「降低錯誤機率」的特性,科學家發現,由於DNA轉錄成mRNA的時候難免會「抄錯」,就好像有一次班上同學抄作業,不小心竟然把對方的學號也抄上去了,唉~真是傷腦筋,怎麼辦呢?老天爺早就為我們想好囉!
➤相同的胺基酸大部分前兩個密碼子相同:例如:故意讓ACU、ACC、ACA、ACG都可以轉譯成蘇氨酸(Thr),這樣就算不小心有幾個核苷酸抄錯,也可以產生相同的胺基酸。
➤同類的胺基酸大多有兩個相同的密碼子:例如:故意讓ACU、ACC、ACA、ACG都可以轉譯成蘇氨酸(Thr);UCU、UCC、UCA、UCG都可轉譯成絲氨酸(Ser),而蘇氨酸(Thr)與絲氨酸(Ser)均為親水性胺基酸,這樣就算產生不正確的胺基酸序列,也可以具有相似的性質,保持蛋白質的立體結構不會因為少數胺基酸序列錯誤而改變。
【請注意】上述內容經過適當簡化以適合大眾閱讀,與產業現狀可能會有差異,若您是這個領域的專家想要提供意見,請自行聯絡作者;若有產業與技術問題請參與社群討論。